背景
现如今我们有了许多深度学习的框架,例如 TensorFlow、PyTorch、MXNet 等等。同时我们还要将其部署于不同的硬件之上,除了常见的 GPU 和 CPU,还有针对于机器学习设计的硬件,例如来自 Google 的 TPU、海思的 NPU、Apple 的 Bonic 等等。
这种场景有没有让你想起传统的编译器?以 LLVM 作为例子,其可以接受不同的语言(C++、Swift、Rust)作为输入,转换成中间表示之后就可以转换成对应于不同平台(x86、ARM)的代码。论文中所描述的系统主要工作是以不同框架的模型作为输入,再输出至不同平台,这也就是为什么被称之为深度学习编译器。
深度学习编译器的整体工作流程如下图,分为前端和后端两部分。编译器将不同框架中的模型作为输入,前端主要是负责与硬件无关的处理。编译器普遍用计算图(Computation Graph)来表示模型结构,落到实际中则是用 High-level IR 表示来表达计算图和控制流。前端会首先将不同框架的输入转换至使用 High-level IR 表示统一的格式,之后会对其进行一些硬件无关的优化,再将其送给后端。
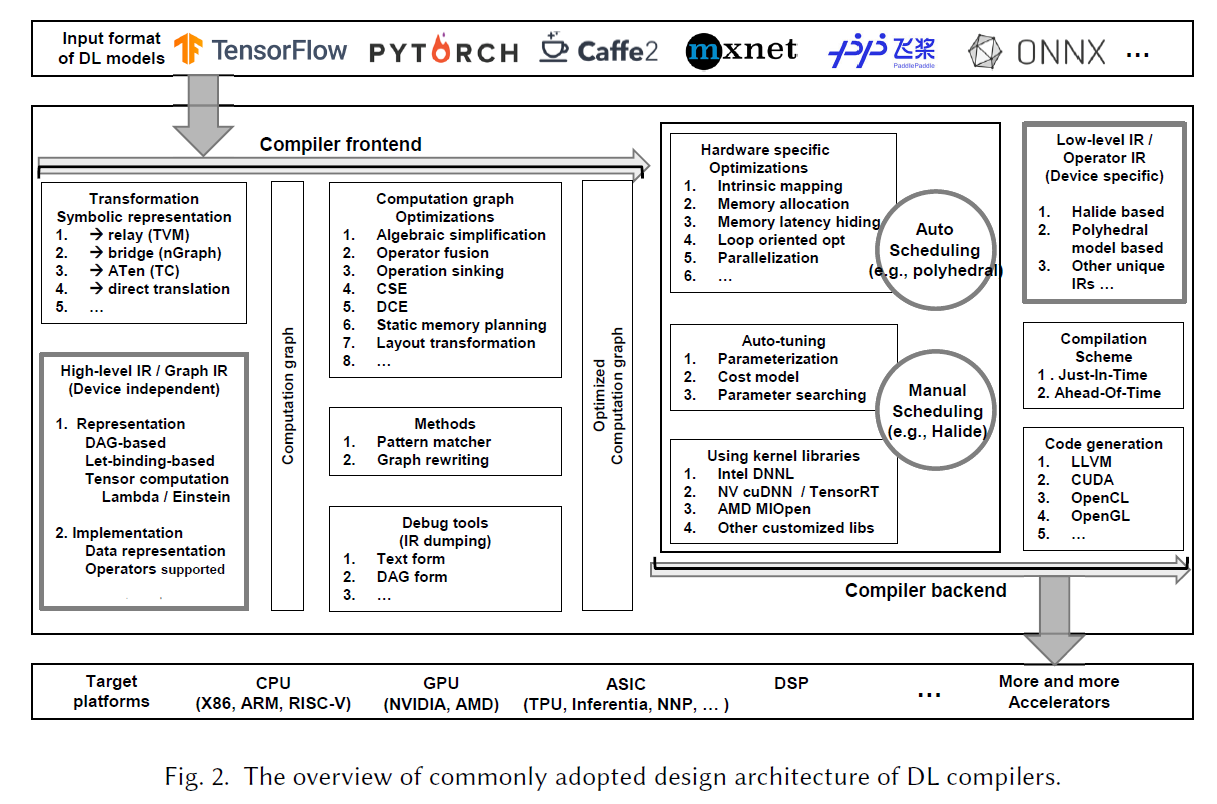
后端也拥有自己的中间表示,称为 Low-level IR,主要工作是将 High-level IR 转化为 Low-level IR,然后针对于输出硬件进行一些特定的优化,并最后编译到对应的硬件指令或者是对应的语言。
文中表 1 对几个常见的编译器(TVM、TC、Glow、nGraph+PlaidML、XLA)在编程语言、支持的硬件、支持的框架、支持生成的语言以及支持的特性几个方面作了直观的对比。
深度学习框架
文中对常见的深度学习框架进行了梳理,例如 TensorFlow、Keras、PyTorch 等等,以及许多已经消失于历史长河之中的框架。其中值得注意的是 ONNX (Open Neural Network Exchange),其定义了一个可伸缩的计算图模型,所以所有支持 ONNX 的框架之间模型可以十分轻松的转换,因此可以用 MXNet 构建模型然后用 PyTorch 运行。
深度学习硬件
文中将深度学习硬件分为了三类:
- 通用硬件(General-purpose Hardware):为通用领域设计的硬件。代表就是 GPU,其并非设计用于深度学习,但是其高度并行化和众核设计十分适合该场景。
- 专用硬件(Dedicated Hardware):专为深度学习计算定制的硬件。最知名的就是 Google 的 TPU,其中包含了专门用于矩阵乘法、激活函数等等的单元,从而加速了深度学习相关的计算。
- 神经形态硬件(Neuromorphic Hardware):模拟生物大脑而设计的芯片。文中提到了来自 IBM 的 TrueNorth 和 Intel 的 Loihi。
核心组件设计
编译器主要分为前后端,分别针对于硬件无关和硬件相关的处理。每一个部分都有自己的 IR (Intermediate Representation,中间表达),每个部分也会对进行优化,从而构成了编译器核心的四个组件。
High-level IR
High-level IR 也称为 Graph IR,用于表示计算图,其出现主要是为了解决传统编译器中难以表达深度学习模型中的复杂运算这一问题,为了实现更高效的优化所以新设计了一套 IR。
High-level IR 的表示分为下面两种:
- DAG-based IR:是一种最为传统的方式,用点和边组织成一个有向无环图(Directed Acyclic Graph, DAG),从而充分利用现有的极其充分的 DAG 优化算法,而且实现简单,但是缺少计算域的定义会导致语义的二义性。
- Let-binding-based IR:Let-binding 其实类似于变量定义,用于定义一个具有作用域的表达式。这样计算时就不必像 DAG 一样递归的计算一个个点,而是可以将每个 let 定义的结果建立一个映射表,之后查表即可。
此外不同的 IR 还有不同的方式表示 tensor 之间的运算,主要分为如下三类:
- Function-based:用函数来封装操作符,XLA 的 IR 采用此种形式。
- Lambda expression:通过变量绑定和替换来描述计算(?),TVM 采用这种形式。
- Einstein notation:也称为爱因斯坦求和约定(summation convention),这种表达方式下无需定义中间变量,IR 可以通过未定义变量的出现找出真正的表达式,TC 采用这种形式。
上面这部分有点难以表达,看了不同编译器的实现就可以很直观感受了
在实际实现过程中还会遇到的一个问题是数据的表示,如下是常用的技术
- 占位符:占位符指用一个只有形状信息的变量来代表一个 tensor,直到运算时再用数据进行填充。这样再构建计算图时就不必关心真正的数据元素,从而将计算图定义和执行分离,方便调整。
- 未知形状表示:这一技术常用于定义占位符,因为有些层的形状直到运行时才能知道形状,这也导致了对于边界和维数的检查需要放宽,也需要额外的机制来保证内存有效。
- 数据布局:数据布局描述了 tensor 如何在内存中组织,通常是从逻辑下标到内存下标的映射。值得注意的是数据布局信息可以和运算符放在一起,而非直觉上和 tensor 自己存放在一起,这样可以更好的实现特定的运算符,减少编译的开销。
- 边界推断:用于编译深度学习模型时决定迭代器的边界,主要是决定占位符的大小。
此外 IR 设计时还需要考虑到对操作符的支持,除了算术操作符(+、-),还有神经网络操作符(卷积、池化),张量操作符(reshape、resize),广播和规约操作符(min、argmin)和控制流操作符(条件和循环),以及用户自定义的操作符。
Low-level IR
Low-level IR 能够在更细粒度的层面上表示模型,从而能够针对于硬件进行优化,文中将其分为了三类
- Halide-based IR:Halide 基本思想为将计算和调度分离。相较于直接给定一个特定的模式,Halide 会尝试各种可能的调度方式并选择最好的一个。
- Polyhedral-based IR:Polyhedral 模型使用 linear programming, affine transformations 以及其他的数学方法来优化具有静态控制流边界和分支的以循环为基础的代码。
- 其他 IR:也有其他的编译器采用了除了以上两种方式之外的 IR,然后将硬件优化交给 LLVM IR 等设施,MLIR 就是一个例子。
以上也反映了最后代码生成部分的不同思路,尽管多数编译器会最后转换成 LLVM IR 从而利用其成熟的优化器和代码生成器,但是将深度学习的代码直接交给 LLVM 之类的传统编译器很有可能会生成质量恶劣的代码,所以通常为了能够针对硬件更好的优化会 1) 在 LLVM 上层先进行优化(Halide-based IR 和 polyhedral-based IR)或者 2) 提供更多额外信息给优化 pass。
编译时也存在两种方式:JIT(just-in-time)和 AOT(ahead-of-time)。JIT 在运行时生成代码,能够根据运行情况优化代码,而 AOT 则是先生成二进制代码再运行,因此可以在编译时进行更大范围的静态分析,此外还可以交叉编译用于嵌入式平台。
前端优化
前端优化发生于计算图构建完成后,输入后端前,主要目标是优化计算图,因此是硬件无关的。优化通常是以一个称为 passes 的东西定义,通过遍历图和转化图结构来进行优化,文中将优化分为三个级别
- Node-level optimizations:结点级别的优化指的是在结点内部进行优化,包括删除结点或者替换成一个更低开销的结点,例如清除 Nop 指令(Nop Elimination)和 0 维度的 tensor (Zero-dim-tensor elimination)。
- Block-level optimizations:块级别的优化可以优化结点之间的关系。Algebraic simplification 可以通过调整运算顺序、结点间结合关系等等方式替换一个高开销的运算符或者是将常量间操作替换成结果(常量折叠)等等。Operator fusion 可以融合运算符,比如减少内存分配次数,结合循环,减少同步的开销等等。Operator sinking 能够将一些操作放到相近的位置,创造更多的机会进行优化。
- Dataflow-level optimizations:数据流级别的优化,文中提到了四种。Common sub-expression elimination 也就是如果一个值常被计算得到但不会变化,那么后续不再计算。Dead code elimination 删除了无法抵达的代码(通常是由优化导致的)。Static memory planning 尽可能的重用内存。Layout transformation 生成更好的数据布局,不过这部分可能会依赖于硬件。
文中还针对于 TensorFlow XLA 做了一个案例介绍,在此不再赘述。
后端优化
后端优化首先就是针对于硬件的优化,从而生成更加高效的代码。一种方法是利用 LLVM,另一种方法是用深度学习领域定制的优化。
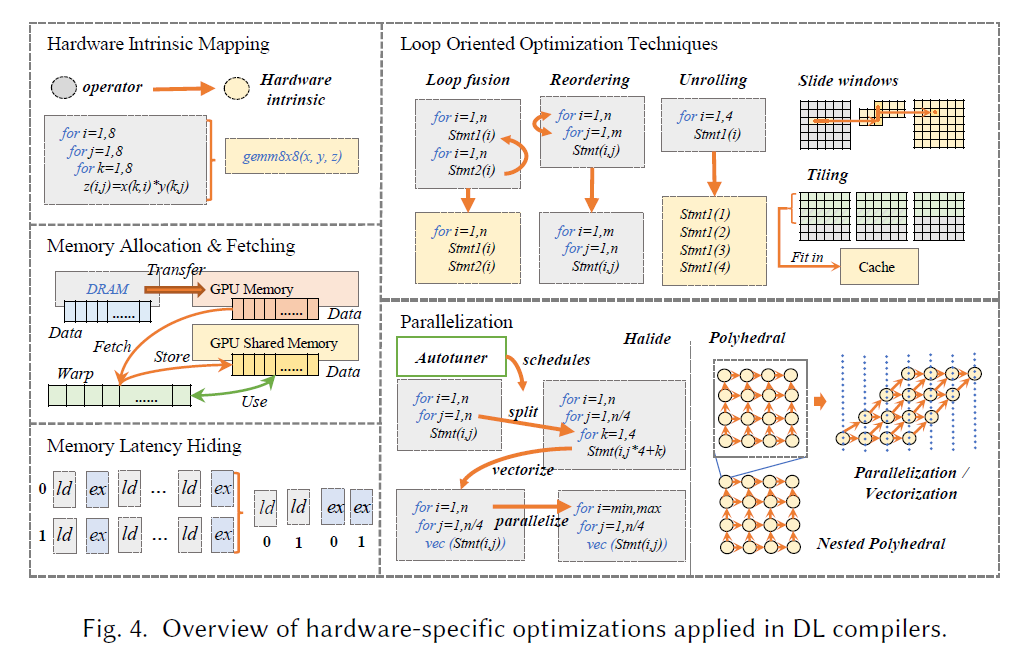
- Hardware intrinsic mapping:将一段 low-level IR 转化成硬件上已高度优化的指令。
- Memory allocation and fetching:GPU 上有专有的内存和共享的内存,两者容量和延迟均不同,因此存在不同的调度策略。
- Memory latency hiding:利用流水线,通过重排指令将访存的指令尽可能靠近从而一次取出更多数据,访存同时执行之前的代码,减少内存延迟的影响。
- Loop oriented optimizations:文中提到了 loop fusion(融合相同边界的循环), sliding windows(循环计算的变量仅在使用时计算,但会导致两个循环串行化), tiling(拆分循环为几部分,更好的利用局部性), loop reordering(修改循环内部代码顺序), and loop unrolling(展开循环再采用更多的优化方法)等方法优化循环。
- Parallelization:将代码并行化以充分利用硬件性能。
在优化过程中许多场景下有许多参数可以调整,因此后端优化的另一方向就是自动调优(Auto-tuning),分为如下几个部分
- Parameterization:将数据中特征和优化选项作为参数提取出来。
- Cost model:用于评估模型的性能,分为三类 1)黑盒模型,只考虑运行时间,简单但是缺少指导优化的信息,2)ML为基础的模型,用机器学习的方法预测性能,能够在找到新配置时更新模型提升准确率,3)预定义的模型,根据编译任务的特征建立一个可以评估任务性能的模型,相比 ML 模型计算花费小,但是换到新任务上就需要重建模型。
- Searching technique:搜索最佳的参数。首先需要对其初始化并决定搜索空间,之后可以采用基因算法、模拟退火算法、强化学习等方法进行搜索。
- Acceleration:加速调优,主要分为两个方向,1)并行化和 2)配置重用,用之前的调优配置加速搜索。
最后是采用已经被高度优化过后的核心库,例如来自 NVIDIA 的 cuDNN 和 Intel 的 DNNL 等等以充分利用硬件。
未来
文章最后作者对于深度学习编译器的未来提出了几个方向:
- Dynamic shape and pre/post processing:动态形状的模型还可以变得更高效。同时模型变得很复杂,不可避免将数据处理放进模型,而预处理和后处理现在还是由 Python 的解释器在执行,容易成为性能瓶颈,所以可以考虑让深度学习编译器加入更多的控制流从而实现对数据处理部分代码一同进行优化。
- Advanced auto-tuning:如今的自动调优着重于单独的操作符,但局部最优并不能产生全局最优,作者提出可以考虑两个不同操作符间操作的调优。
- Polyhedral model:一方面自动调优可以用先前的配置降低多面体模型的开销,另一方面多面体模型自动调度可以减少自动调优时的搜索空间,从而提高整体的效率。
- Subgraph partitioning:将计算图分割成数个子图,然后针对各个子图再进行各自的处理。
- Quantization:传统的量化策略只是用固定的几种策略,而在深度学习编译器中则可以利用编译过程中优化机会获得更有效地量化策略。
- Unified optimizations:作者提出不同的编译器间难以分享最新的优化手段,因此提出可以统一优化的过程从而重用优化的方法。
- Differentiable programming:微分编程好像是个很有趣的方向,不过目前对于深度学习编译器来说还是个十分具有挑战性的方向。
- Privacy protection:作者提到在边缘-云系统中,边缘设备和云设备通信过程中被窃听,攻击者就可以用中间结果训练另一个模型来获取隐私信息。一个解决方法是添加噪声,但在哪里添加噪声和如何自动添加噪声都是研究方向。
文中出现任何错误或者对于论文内容想要进行探讨,可以在网页最下方找到联系方式邮件联系我,共同学习进步